This article is copied from
search business intelligence blog
Bill Inmon’s enterprise data warehouse approach (the top-down design): A normalized data model is designed first. Then the dimensional data marts, which contain data required for specific business processes or specific departments are created from the data warehouse.
Ralph Kimball’s dimensional design approach (the bottom-up design): The data marts facilitating reports and analysis are created first; these are then combined together to create a broad data warehouse.
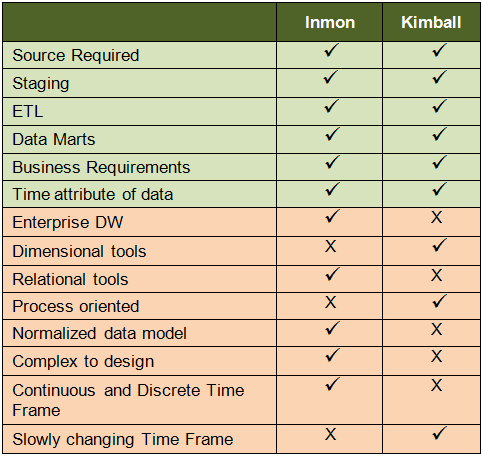 |
| Kimball vs Inmon data warehouse models |
Which one to pick ?
Insurance: It is vital to get the overall picture with respect to individual clients, groups, history of claims, mortality rate tendencies, demography, profitability of each plan and agents, etc. All aspects are inter-related and therefore suited for the Inmon’s approach.
Marketing: This is a specialized division, which does not call for enterprise warehouse. Only data marts are required. Hence, Kimball’s approach is suitable.
CRM in banks: The focus is on parameters such as products sold, up-sell and cross-sell at a customer-level. It is not necessary to get an overall picture of the business. For example, there is no need to link a customer’s details to the treasury department dealing with forex transactions and regulations. Since the scope is limited, you can go for Kimball’s method. However, if the entire processes and divisions in the bank are to be linked, the obvious choice is Inmon’s design vs. Kimball’s.
Manufacturing: Multiple functions are involved here, irrespective of the budget involved. Thus, where there is a systemic dependency as in this case, an enterprise model is required. Hence Inmon’s method is ideal.